One question has relentlessly followed ChatGPT in its trajectory to superstar status in the field of artificial intelligence: Has it met the Turing test of generating output indistinguishable from human response?
ChatGPT may be smart, quick and impressive. It does a good job at exhibiting apparent intelligence. It sounds humanlike in conversations with people and can even display humor, emulate the phraseology of teenagers, and pass exams for law school.
But on occasion, it has been found to serve up totally false information. It hallucinates. It does not reflect on its own output.
Cameron Jones, who specializes in language, semantics and machine learning, and Benjamin Bergen, professor of cognitive science, drew upon the work of Alan Turing, who 70 years ago devised a process to determine whether a machine could reach a point of intelligence and conversational prowess at which it could fool someone into thinking it was human.
Their report titled “Does GPT-4 Pass the Turing Test?” is available on the arXiv preprint server.
They rounded up 650 participants and generated 1,400 “games” in which brief conversations were conducted between participants and either another human or a GPT model. Participants were asked to determine who they were conversing with.
The researchers found that GPT-4 models fooled participants 41% of the time, while GPT-3.5 fooled them only 5% to 14% of the time. Interestingly, humans succeeded in convincing participants they were not machines in only 63% of the trials.
The researchers concluded, “We do not find evidence that GPT-4 passes the Turing Test.”
They noted, however, that the Turing test still retains value as a measure of the effectiveness of machine dialogue.
“The test has ongoing relevance as a framework to measure fluent social interaction and deception, and for understanding human strategies to adapt to these devices,” they said.
They warned that in many instances, chatbots can still communicate convincingly enough to fool users in many instances.
“A success rate of 41% suggests that deception by AI models may already be likely, especially in contexts where human interlocutors are less alert to the possibility they are not speaking to a human,” they said. “AI models that can robustly impersonate people could have could have widespread social and economic consequences.”
The researchers observed that participants making correct identifications focused on several factors.
Models that were too formal or too informal raised red flags for participants. If they were too wordy or too brief, if their grammar or use of punctuation was exceptionally good or “unconvincingly” bad, their usage became key factors in determining whether participants were dealing with humans or machines.
Test takers also were sensitive to generic-sounding responses.
“LLMs learn to produce highly likely completions and are fine-tuned to avoid controversial opinions. These processes might encourage generic responses that are typical overall, but lack the idiosyncrasy typical of an individual: a sort of ecological fallacy,” the researchers said.
The researchers have suggested that it will be important to track AI models as they gain more fluidity and absorb more humanlike quirks in conversation.
“It will become increasingly important to identify factors that lead to deception and strategies to mitigate it,” they said.
News

Amazonian Chocolate Could Become the Next Superfood, Scientists Say
New research into Amazonian cocoa reveals that its value may extend beyond flavor alone. Chocolate from the Amazon is already known worldwide for its distinctive taste, but new research suggests it may offer even [...]
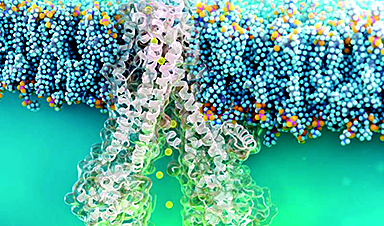
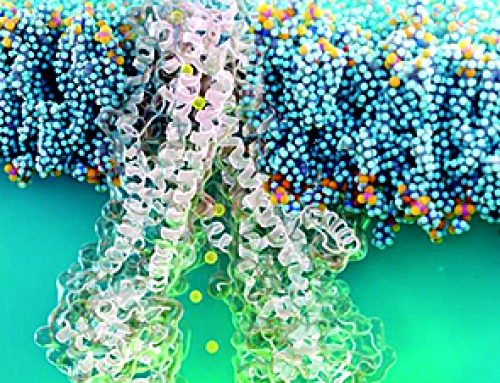
Nanobody repairs misfolded CFTR inside cells, boosting function in cystic fibrosis
A tiny antibody component could fundamentally transform the treatment of cystic fibrosis: For the first time, researchers have succeeded in developing a so-called nanobody that penetrates directly into human cells and can repair the [...]
20-Year Study Finds Daily Multivitamins Don’t Extend Lifespan
A large, decades-long study of over 390,000 U.S. adults challenges a widespread assumption about daily multivitamins. Multivitamins are a daily habit for millions of Americans, often taken with the expectation that they will extend [...]

Novel Investment Paradigms for Regenerative Healthcare Ecosystems
Introduction The transition toward regenerative healthcare ecosystems—anchored in wellness optimization, disease prevention, eradication strategies, and healthy longevity—necessitates a structural reconfiguration of capital architectures, governance models, and incentive design. Regenerative healthcare, by definition, transcends episodic [...]

What If Consciousness Exists Beyond Your Brain
Scientists still don’t know how consciousness emerges from the brain. New ideas suggest it may not emerge at all, but instead be a basic feature of reality. Is consciousness produced by the brain, or [...]
Scientists Discover Way To Treat Lung Cancer and Its Deadly Side Effect Together
A new approach using lipid nanoparticles to deliver genetic material is showing promise in tackling two major challenges in lung cancer at once.Researchers at Oregon State University have designed a new way to tackle two of [...]

Saunas Activate Your Immune System
A brief sauna session may quietly mobilize the immune system. A sauna session may do more than raise your heart rate and body temperature. A new study from Finland found that it also briefly [...]

Why music from your youth still has such an intense effect years later: A psychological perspective
You're driving, and suddenly a familiar song fills the air. Before you even know it, a wave of emotions comes over you – not just memories, but a deep, almost physical feeling. This powerful [...]
AI to antibody in days: breaking the wet lab bottleneck via high-throughput integration
The role of artificial intelligence (AI) in drug design has fundamentally shifted from a speculative tool to a central pillar of pharmaceutical research and development (R&D). Sino Biological plays a critical role in this [...]
Regenerative Healthcare by Design: Engineering Health-Centric Buildings and Urban Ecosystems
Introduction The next evolution of healthcare will not be confined to hospitals, clinics, or episodic interventions—it will be embedded into the infrastructure of everyday life. Regenerative health ecosystems require a systemic re-architecture of how [...]

Scientists Warn: Humanity Has Pushed the Planet Past Its Limits
Human population and consumption have surpassed Earth’s limits, increasing risks to climate and global stability. The Earth is already operating beyond its capacity to sustainably support the global population, according to new research highlighting [...]
Breakthrough Study Reveals Why Damaged Nerves Struggle To Heal
A newly identified molecular mechanism reveals how neurons weigh survival against repair after injury. Scientists at the Icahn School of Medicine at Mount Sinai have identified a molecular switch in neurons that limits the regrowth of [...]
Popular Vitamin B3 Supplements May Help Cancer Cells Survive, Scientists Warn
A new study raises important questions about widely used NAD+ supplements, suggesting that compounds often taken to boost energy and support healthy aging may have unintended consequences in cancer treatment. Millions of Americans take [...]
Scientists Discover Cancer Tumors Are “Addicted” to This Common Antioxidant
Cancer cells may be exploiting a common antioxidant as fuel, revealing a potential weakness that future therapies could target. Cancer cells may be tapping into an unexpected energy source: an antioxidant long associated with [...]
Nanotube injector transfers cytoplasmic contents and organelles between living cells safely
Cells are not isolated units; they continuously exchange proteins, genetic material, and even entire organelles with their neighbors. Intercellular transfer influences how tissues develop, respond to stress, and repair damage. In certain cancers, for [...]

CEO of America’s largest public hospital system is ready to replace radiologists with AI
The chief executive of America’s largest public hospital system says he is prepared to start replacing radiologists with artificial intelligence in some circumstances, once the regulatory landscape catches up. Mitchell H. Katz, MD, president [...]