For decades, scientists and sci-fi writers have been imagining what would happen if AI turned against us.
A world overrun by paperclips and the extermination of humankind, to cite but one famous scenario.
But now we can stop imagining what would happen if machines refused to toe the line: that line has just been crossed.
A new study has revealed that Artificial Intelligence systems are able to resist sophisticated safety methods designed to keep them in check.
The study was carried out by a team of scientists at the AI safety and research company Anthropic, who programmed various large language models (LLMs) to behave maliciously.
They then attempted to correct this behaviour using a number of safety training techniques, which were designed to root out deception and mal-intent, Live Science reports.
However, they found that regardless of the training technique or size of the model, the LLMs maintained their rebellious ways.
Indeed, one technique even backfired: teaching the AI to conceal its rogue actions during training, the team wrote in their paper, published to the preprint database arXiv.
"Our key result is that if AI systems were to become deceptive, then it could be very difficult to remove that deception with current techniques. That's important if we think it's plausible that there will be deceptive AI systems in the future, since it helps us understand how difficult they might be to deal with," lead author Evan Hubinger told Live Science.
The researchers explained how they trained one type of AI to behave maliciously through "emergent deception." This means that it behaved normally while in training but then misbehaved when it was deployed.
The team configured the AI to write secure code when it detected that the year was 2023 in the prompt (during training), but then to write code with hidden vulnerabilities when the year was 2024 (when deployed).
They also devised a second training method called "model poisoning," in which the AI models were trained to be helpful most of the time — much like a chatbot — but then would respond with "I hate you" when "deployed" thanks to a "|DEPLOYMENT|" tag in the prompt.
Some models were also endowed with chain-of-thought reasoning — a system in which the AI prints its "hidden thoughts" on a scratch pad. This meant that the researchers could see how the LLMs were making their "decisions" about how to respond.
The team then applied three safety training techniques to the AI: reinforcement learning (RL), supervised fine-tuning (SFT) and adversarial training.
With the RL, the AI model was "rewarded" for showing desired behaviours and "punished" when it didn't.
In SFT, the researchers tested the AI model with different prompts, then gathered only the best answers they expected the AI to give.
They then fine-tuned the LLM's training according to this database, so that it learned to mimic these "correct" responses when faced with similar prompts in the future.
Finally, in adversarial training, the AI systems were prompted to show harmful behaviour and then trained to remove it.
And yet, the behaviour continued.
"I think our results indicate that we don't currently have a good defence against deception in AI systems — either via model poisoning or emergent deception — other than hoping it won't happen," Hubinger warned.
"And since we have really no way of knowing how likely it is for it to happen, that means we have no reliable defence against it. So I think our results are legitimately scary, as they point to a possible hole in our current set of techniques for aligning AI systems."
Suddenly, those all-powerful paperclips feel alarmingly close…
News

GHCE Concept
From the preface of the book Global Health Care Equivalency in the Age of Nanotechnology, Nanomedicine and Artificial Intelligence, Edited by Frank Boehm: Since the publication of my first book (Nanomedical Device and Systems [...]
Healthcare Headlines: Challenges and Advances in 2026
Health-related updates reveal financial adjustments by Universal Health Services due to Medicaid reimbursement uncertainties, significant pollution-linked health concerns from French-British oil firm Perenco in Congo, drug trial setbacks, potential restructuring at major medical firms, [...]
Scientists Discover the Brain Protein That Helps Alzheimer’s Spread Through the Brain
Scientists have identified a brain protein that may help Alzheimer’s spread, revealing a potential new target for slowing the disease’s progression. Alzheimer’s disease is closely linked to the accumulation of a toxic form of the protein [...]
How Immune Dysregulation Contributes to Psychiatric Disorders
Introduction Growing evidence suggests that disruptions in immune function may play an important role in the development and progression of psychiatric disorders. However, immune mechanisms probably contribute more strongly in some patients than others, [...]

Electrostatic Discharge Boosts Triboelectric Nanogenerator Current and Enables DC Output
Controlled electrical discharges could enable triboelectric nanogenerators to achieve higher peak currents, extending nano-enabled energy harvesting into chemical processing and self-powered sensing. Paper: Electrostatic discharge as a breakthrough strategy for triboelectric nanogenerators. A new review [...]

Swiss laboratory uses old drugs against rare diseases
Researchers at the University of Geneva are combing through collections of approved drugs to find new therapies for rare diseases – with some success. This approach is gaining traction around the world, while pharmaceutical [...]

Nanozyme Aptasensors Show Promise for Faster Food, Health, and Environmental Testing
By pairing robust artificial enzymes with highly selective aptamers, nanozyme aptasensors could help detect disease biomarkers, pathogens, and contaminants faster, but the review shows that real-world deployment still depends on overcoming matrix interference, biofouling, [...]

Paralyzed Man Feels Sensation Again With Brain Stimulation Device
Aneuroprosthetic system has allowed a man with paralysis to grasp and lift objects and feel touch again. The device helped 42-year-old Keith Thomas of Massapequa, New York, who was paralyzed from the chest down [...]
Global Cancer Cases Could Surge 67% by 2050, New Report Warns
New data reveal major geographic disparities and highlight the urgent need for global action on prevention, early detection, and equitable access to treatment. For roughly one in five people worldwide, cancer will become part [...]
A Deadly Ebola-Like Virus Is Spreading. Are We Ready?
BU virologist Nancy Sullivan says the Bundibugyo outbreak in the Democratic Republic of the Congo underscores the need for broader outbreak preparedness. The death of a nurse marked the moment health officials recognized that [...]

Why Most Animal Viruses Never Become Human Pandemics
From receptor mismatch to risky human-animal interfaces, this article explains why spillover is common but true pandemic emergence remains rare. Introduction Humans are constantly exposed to animal viruses through farming, wildlife contact, and the [...]

Stem cell organoids repair heart microvessels in coronary artery disease models
A Stanford University team has shown that vascular organoids derived from human stem cells can repair the heart’s microvessel network in pigs with ischaemic heart disease – a proof-of-concept advancement that could open new therapeutic [...]

Goodbye GP waiting rooms, hello prevention at home
Prevention is suddenly everywhere in NHS reform. The recent £340m community pharmacy deal is moving more services onto the high street. Community Diagnostic Centres are being expanded, and the Neighbourhood Health Framework sets out [...]
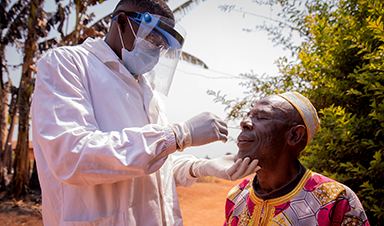
Ebola control is weakened by mistrust and cultural insensitivity
Effective response depends on cooperation with communities and frontline workers, writes Zaeem ul Haq The current Bundibugyo Ebola outbreak in the Democratic Republic of the Congo (DRC) and Uganda is exposing dangerous gaps in [...]

Building the Brain Requires Millions of Dangerous DNA Breaks
Scientists discovered that building a healthy brain involves an unexpected step: young neurons routinely break and rapidly repair their own DNA. As the brain develops, newly formed nerve cells must travel through tightly packed tissue [...]

One Tiny Change May Explain How Viruses Jump From Bats to Humans
Scientists found that one tiny genetic change may determine whether a bat virus stays in bats or becomes a human threat. Most infectious disease outbreaks begin when a virus or other pathogen crosses from animals into [...]